关键词: C10K,select/poll,epoll/kqueue,libevent
C10K
单台服务器承受10000QPS(每秒并发量),简单的理解就是10000个Socket连接到服务器我们要如何处理?
- 一. 为每个Socket连接创建一个进程;可以试试在自己电脑开1W个进程试试,上下文切换会出现明显的『抖动』,所以基于进程的优化长路漫漫。
- 二. 为每个Socket连接创建一个线程;可行的方案,一个进程可以创建1024个线程(1024可修改,不同操作系统不一样),创建10个进程就能创建10000+个线程,但是新的问题又出现,这么多请求CPU处理不了怎么办?
Blocking IO(IO阻塞)
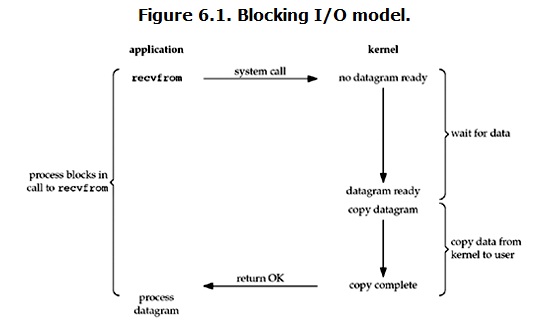
linux下socket都是默认blocking,当一个请求到达kernel,kernel程序开始获取socket数据,此时很多包可能还没及时到达,所以kernel需要等待,同时整个进程会被阻塞。所有数据到达后,kernel会将数据拷贝到用户内存然后返回结果,用户进程才解除block的状态,接受下一次请求。
Blocking IO的两个阶段都发生了blocking,一个是wait for data阶段,一次是copy data from kernel to user阶段;
non-blocking IO(IO非阻塞)
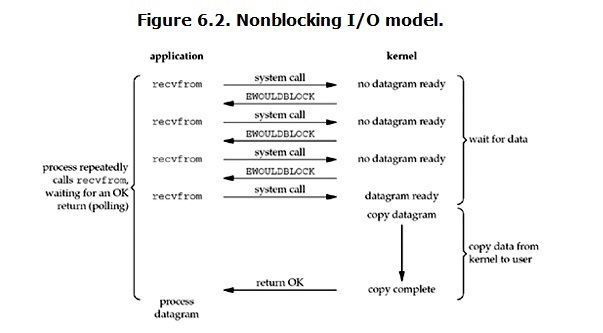
当一个请求到达kernel,kernel会直接向用户进程返回Error。用户进程需要不断的去问kernel数据准备好了没;如果kernel数据准备好,用户进程就会开启block状态,等待kernel将数据拷贝到用户内存然后返回结果。
有个很形象的例子,我们去医院体检,『IO阻塞』的方式就是大家排队依次按顺序做A-Z的体检项目;『IO非阻塞』的方式就是大家自己选择先做哪个后做哪个;对医院来说工作量没有变,但是对用户来讲自由选择的方式更快;
重点:IO非阻塞虽然名字叫『非阻塞』,但是copy data from kernel to user阶段其实处于blocking;
IO multiplexing(IO多路复用)
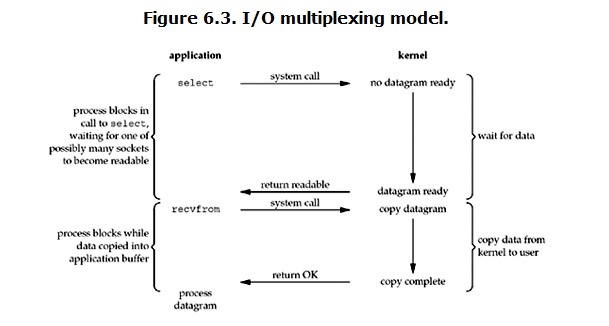
select/poll,epoll/kqueue都基于该模式。在用户进程和kernel之间加了一层select/epoll程序。通过程序去管理更多的连接,从user-threading->kernel变成user-threading->select/epoll->kernel.其中user-threading->select/epoll是非阻塞的,select/epoll->kernel阻塞。
IO multiplexing其实与blocking IO非常相近,而且还多了一次system调用,所以IO multiplexing的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接;所以在并发量不是很大的情况下IO multiplexing的延迟可能会比blocking IO大;
asynchronous IO(异步IO)
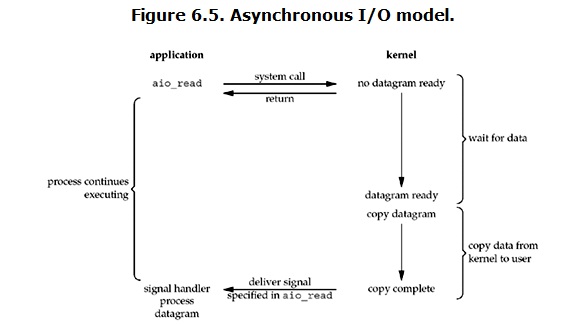
当一个请求到达kernel,kernel会先返回数据,告诉「用户进程」已收到请求你去做其他事吧。等kernel把一切做完会给用户进程发送一个操作完成的signal。所以对于用户进程来说,我只需要发起调用,其他时间可以去做自己的事情;
select/poll
基于IO multiplexing,select程序每次循环检测该socket所有的包是否准备完毕。如果准备完毕就访问kernel,当请求量大了之后每次循环检测socket文件句柄将非常耗时。
epoll/kqueue
在select/poll基础上改进。由于select程序每次循环获取socket文件句柄很耗时,所以在获取socket文件句柄时给该socket设置一个状态,当socket准备完毕之后修改这个状态。所以每次只需要检测状态发生了变化的socket,用空间换时间。
libevent
由于不同操作系统下IO multiplexing实现方式不一样,用户写的程序很难跨平台。libevent就是为去平台差异化出现的。libevent底层做了各个平台的兼容。比如FreeBSD的kqueue,Linux的epoll,Windows的IOCP。libevent会基于平台去选择调用哪些函数;这些对使用者来说是透明的。
总结
越来越多的技术帮助我们解决C10K问题。总结一下根本的思路是要高效的减少blocking,让CPU专心处理核心任务。从blocking IO的两个阶段blocking,non-blocking IO的一个阶段blocking,asynchronous IO的无blocking;
后续
解决C10K问题之后,大家又开始想办法处理 C10M问题,单台服务器承受10000*1024QPS。进程和线程已经无法处理这种数量级的单元。当然已经有应对C10M的解决思路,比如比线程更小的处理单元coroutine(协程)。Golang的goroutine,Python、Lua中的coroutine都证实能达到比线程更好的效果。